k8s有許多指標數據需要搜集, 大致上可以分為兩類: 監控 k8s cluster本身 和 監控Pod;
監控k8s cluster的目的是要確認健康狀況, 包含Node是否正常運行, 系統資源運用狀況及資源利用率等, 通常可以用幾項衡量指標:
K8s的自定義指標API(custom metrics API)和資源指標API(resources metrics API)為用戶提供了自行按需求擴展指標的接口, 它允許用戶自行定義指標類型的API, 這些API通過API聚合器讓開發人員可以輕鬆擴展K8s API指標, K8s的監控系統架構主要是由核心指標流水線和監控指標流水線組成:
核心指標流水線
由 kubelet, 資源評估器, metrics-server以及由API Server提供的API群組組成, 可用於為k8s提供核心指標來了解內部組件及核心程序;提供的相關指標包含:
CPU 使用率, Memory使用率, Pod資源佔用率, container disk使用率等;使用來衡量指標的核心組件有調度邏輯和UI組件。
監控指標流水線
用於從系統蒐集各種指標數據並提供給client、儲存系統以及HPA Controller等使用, 這邊蒐集的數據也稱為非核心指標, 其中也可能包含部分核心指標和其他指標;
自定義指標API允許用戶可以任意擴展應用程式上面的指標, k8s不會提供這些自定義指標的解釋, 必須要依賴第三方解決方案。
HPA Controller可以同時使用資源指標API和自定義指標API, 它可以使用觀察到的指標自動縮放Deployment Controller 或ReplicaSet Controller底下的控管的Pod數。
資源指標API和自定義指標API都只是API的定義和規範, 並非實際的實現, 目前資源指標API的組件為metrics-server, 自定義指標API則是建構在監控系統prometheus上面的k8s-prometheus-adapter, Prometheus是CNCF底下的項目之一, 它擁有k8s系統上眾多組件的支援。
K8s cluster需要部署 Metrics Server 才能使用資源指標API, 資源指標API透過API Server的URL路徑/apis/metrics.k8s.io進行存取, Metrics Server是cluster級別的資源利用率數據聚合器(aggregator), 它透過kube-aggregator註冊到API Server上, 而後基於kubelet的Summary API收集每個節點的指標數據, 再將數據儲存在Memory, 再以指標API格式提供: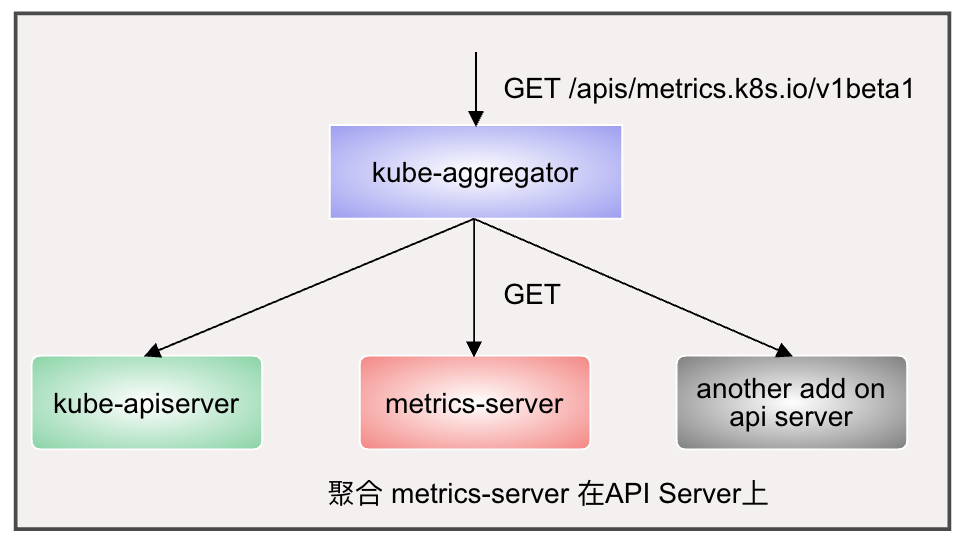
Metrics Server 在每個cluster中只會運行一個, 啟動會自動初始化跟每個節點的關聯, 基於安全性考量不建議將Metrics Server運行在master上面,
配置 metric-server 可以先clone專案
git clone https://github.com/kubernetes-incubator/metrics-server.git
apply
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.7/components.yaml
查看結果
-> % kubectl api-versions | grep metrics
metrics.k8s.io/v1beta1
查看 metrics-server pod 運行結果
-> % kubectl get pods -n kube-system -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
metrics-server-6648f5454b-jl6k9 1/1 Running 0 3m19s
查看Pod中容器的log是否有錯誤提示指令如下kubectl logs metrics-server-6648f5454b-jl6k9 -n kube-system
kubectl get --raw 可以返回cluster中所有節點的資源使用狀況列表
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq
kubectl top 可以查看節點和Pod的資源使用訊息, 包含node和pod兩個子命令, 可以顯示相關的資源佔用率
由於Metrics Server是存在Memory上面, 一但重啟數據就消失, 如果需要保留歷史數據可以改用第三方的監控軟體-Prometheus。
明天來看 Prometheus。


 iThome鐵人賽
iThome鐵人賽